Scratch3技术分析之项目内部数据(第6篇)
文章目录
我们在Scratch3技术分析之创作平台API(第1篇)定义了以下两个名词:
- 项目的内部数据(https://projects.scratch.mit.edu/[project_id])
- 项目的外部数据(https://api.scratch.mit.edu/projects/[project_id])
本文将详细讨论项目的内部数据,看看Scratch是如何精心设计这个数据结构了。
Scratch项目兼容性和可扩展性的秘诀就是精心设计了这个数据结构。
项目的内部数据
我们从一个简单的项目开始。拖动两个积木,拼在一起,保存这个项目,看看提交的项目数据是怎样的。
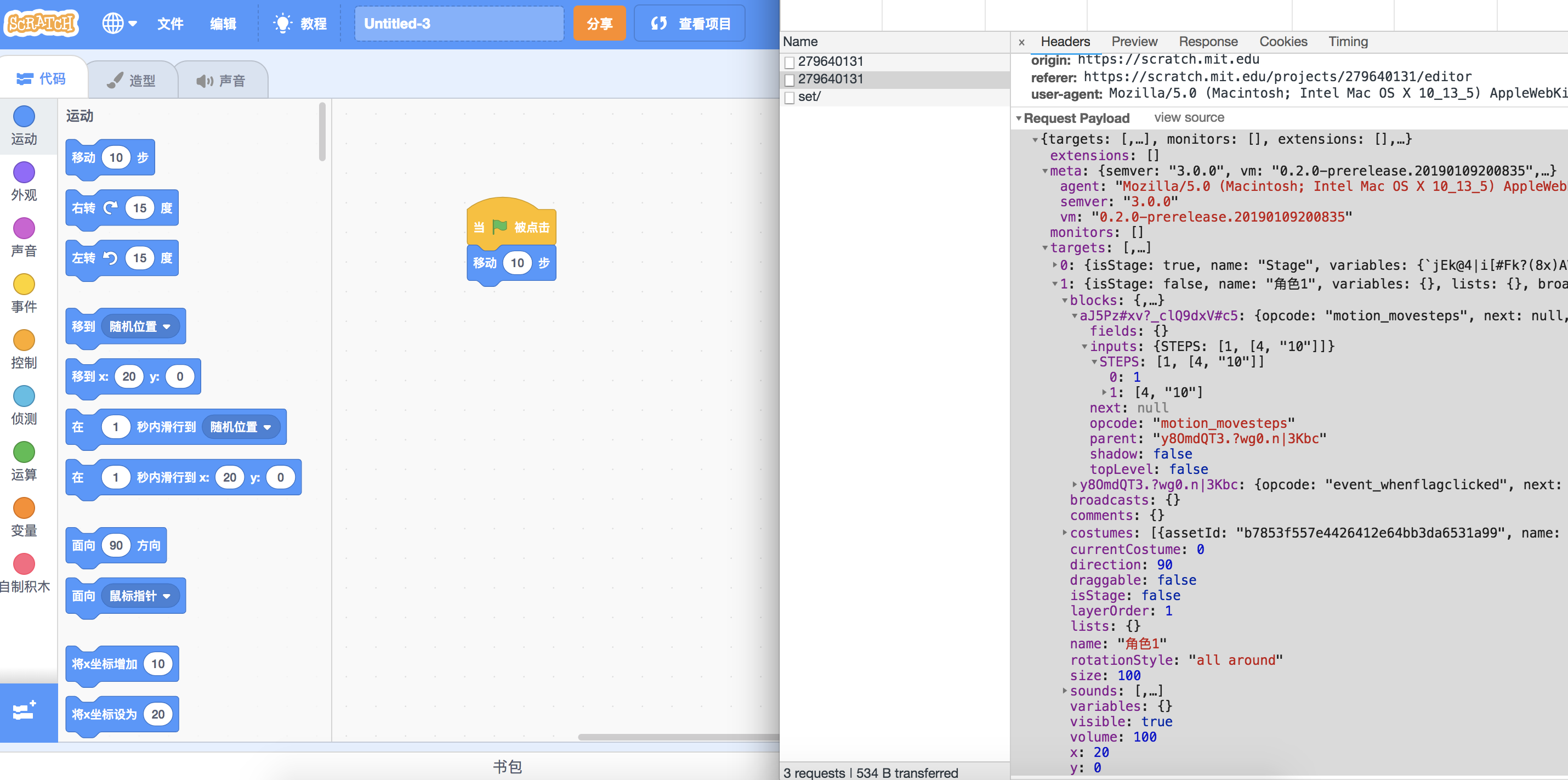
完整的数据为:
|
|
为了获得好的阅读效果,你可以将它们复制到https://jsoneditoronline.org/
顶层结构
最外层的四个key为:
- extensions
- meta
- monitors
- targets
我们逐一分析
extensions
稍后再说
meta
顾名思义,meta保留了元信息。包括以下信息:
|
|
semver描述构建当前项目数据的scratch编辑器的语义版本是3.0.0
vm字段保留了当前项目所用的scratch-vm版本号,有了这个信息,我们就知道项目所依赖的虚拟机(vm)版本,而vm决定了执行项目的环境(支持什么功能/硬件)。有了这些数据,我们就容易平滑升级和追踪问题。
agent描述了客户端的环境。
monitors
暂不讨论
targets
targets是scratch中非常核心的一个概念,我们所做的编程,都是针对targets的编程。这也是Scratch面向对象的地方。Scratch从面向对象语言Smalltalk中学了许多东西。
有两类target: 舞台和角色。
我们前头的积木是针对角色的,所以我们接下来关心角色target。
blocks
积木属于角色,换句话说,角色拥有定义它行为的积木。
我们刚才拖动的2块积木,在项目数据中表示如下
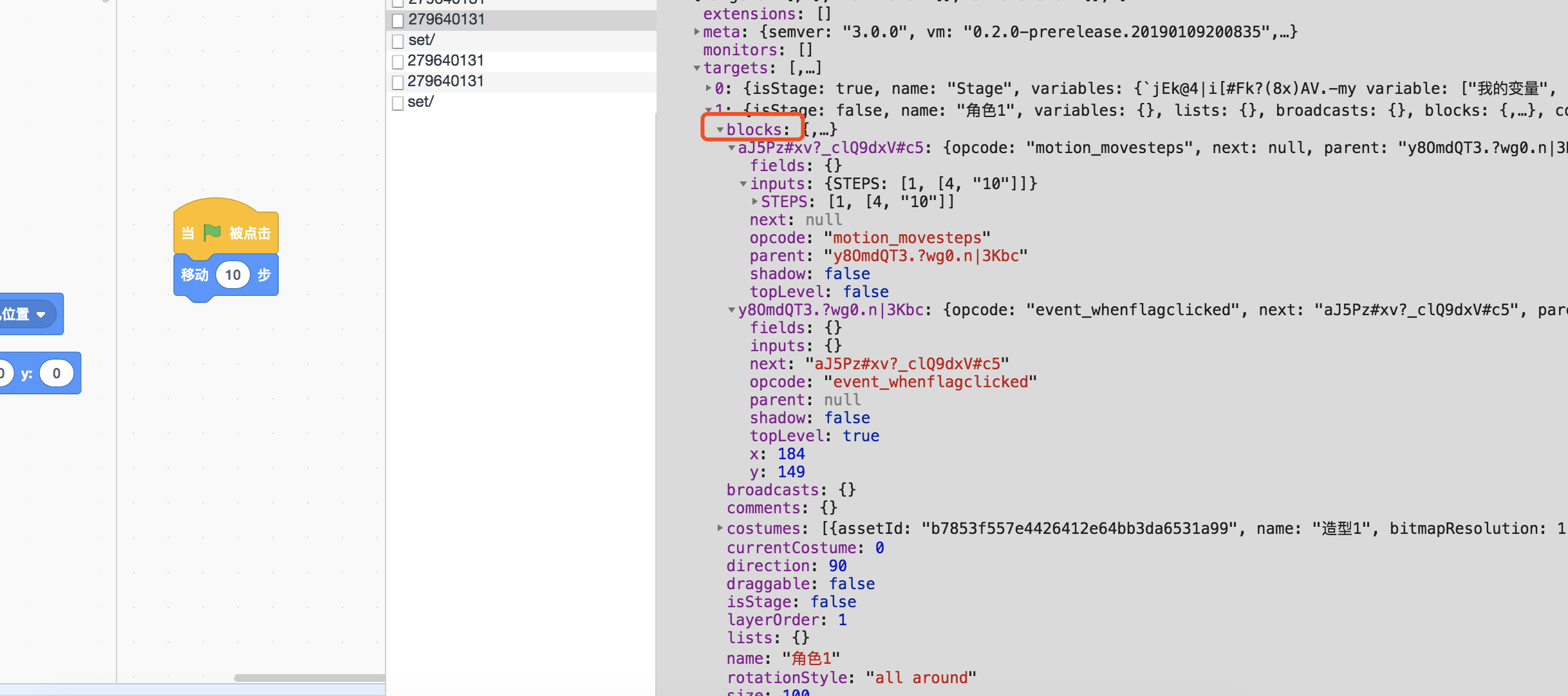
积木的key(id)是随机生成的(由blockly支持)
opcode是积木关联到vm中功能代码(js代码)的钩子。
这是一个展示以下原则的绝佳例子: 表现与实现分离
这个设计是极为聪明的,项目对实际执行它的虚拟机(vm)一无所知,如此一来升级就容易了。
积木直接的连接关系,从上图的属性中,容易看出来。
加了扩展
我们再来看看添加了拓展之后是怎样的。
我们加一个microbit扩展。
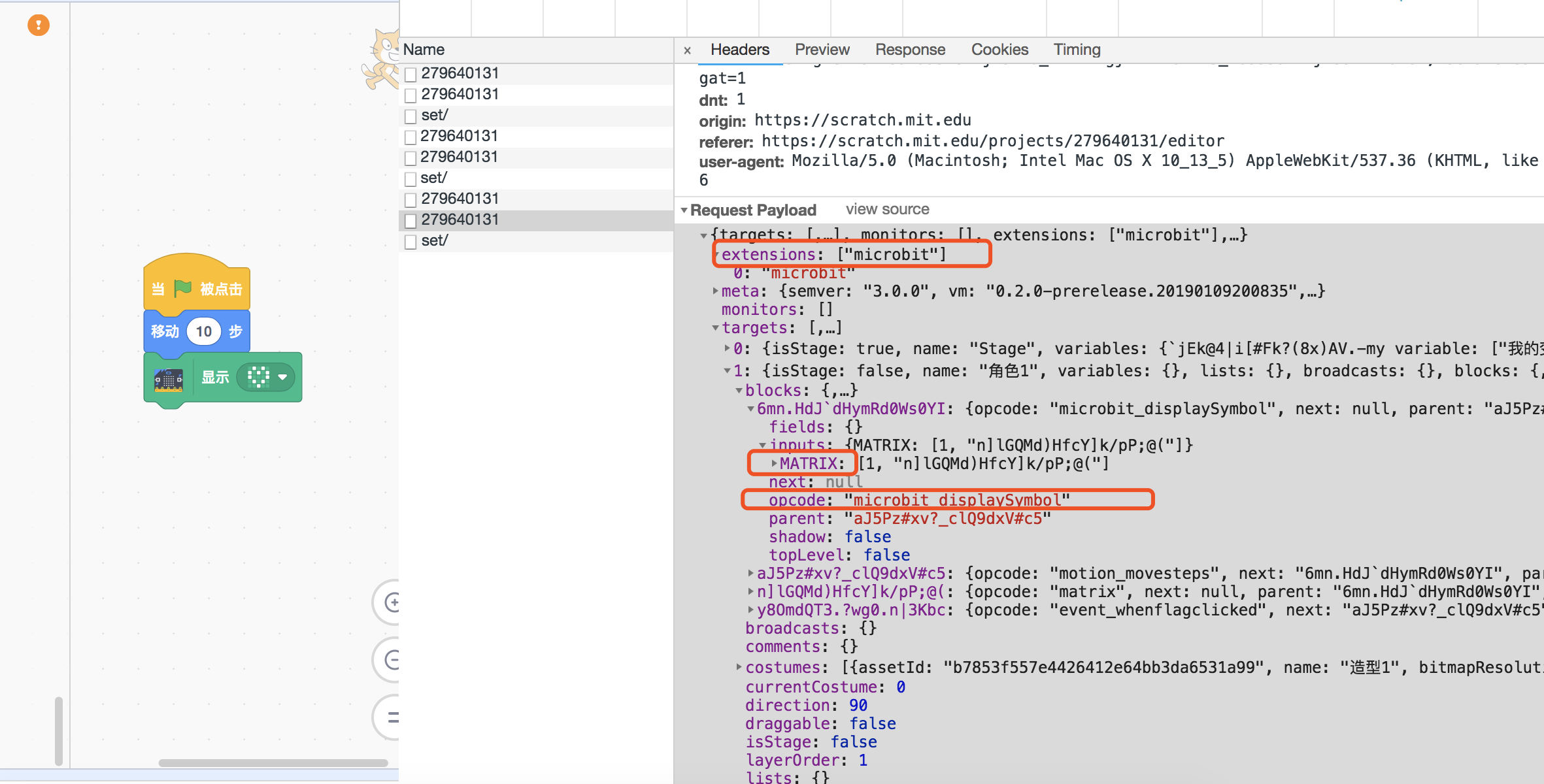
可以看到,顶部的extensions里加上了"microbit"。
值得注意的是,这个积木的输入很有趣,允许用户绘制5x5的矩阵来控制microbit的点阵屏。
这种特殊输入的定义在scratch-blocks中, 参考: Blockly.FieldMatrix = function(matrix)
文章作者 种瓜
上次更新 2019-01-15