可视化筛选你中意的工作
文章目录
晚上到星巴克写作的效率好高!
缘起
在技术这个话题下,我比较形而下,大概算实用主义者,关注技术的现实意义。另一个原因可能是数学不够好,数学好的小伙伴如@sevenry,更多兴趣在探索算法和问题的数学形式。
前段时间有朋友在找工作,作为技术宅,当然不能像一般用户那样找啦,于是小伙伴决定写个爬虫帮忙去搜寻合适的工作。我觉得有趣,那算时间正好在看数据可视化和数据采集相关的书,心痒痒地想试试,于是就用了一个周末时间写了一个爬虫和数据可视化项目,帮助求职者更方便地找到中意的职位
现有问题
一开始在思考,用户上主流的招聘网站寻找合适的职位,是怎样一种体验呢,自己试着用了几个主流网站。体验类似淘宝购物,选择过滤条件,然后逐个职位看过去。其中比较不爽的是,翻了后页,忘了前页,对不同的职位我想做个对比,不得不逐个记下第一印象合格的职位的网址,之后逐个网页打开,做优劣势的比较。十分困难,大脑每次只能处理极少数量的职位和维度(薪资,地理位置,福利),以至于半天没法得出那个更好。想用控制变量来比较,发现工作量很大
构思
在没想清楚怎么做可视化之前,先写了爬虫,采集到数据后,这部分反正不怎么需要思考。看到爬取到的数据有很多个维度之后(薪资,地理位置,福利…),突然想到,这是是个多指标的过滤问题啊,而这个词我在印象笔记里记过,也不知道是不是自创,是对阅读bokeh example app movies项目的批注,这个项目和我将做的事,在模式上是何等相似啊,于是剩下的就是细节工作了
项目细节
项目相关
爬虫部分
我最初想爬取主流招聘网站的数据,考虑到工作量,选取了最喜欢的拉勾网,后期要拓展数据集只是体力活
目前jobSpiderjobSpider是一只爬取拉勾网的scrapy爬虫,用于爬取职位信息。拉钩的数据接口非常漂亮,以至于这个项目本质上都不能算爬虫,它直接请求拉勾网的接口,获得漂亮的json数据,核心代码很短:lagou_spider.py,不用一分钟看完
默认拉勾网会给出最新的5000条数据,如果你想爬取更多(比如研究职位变化趋势、从职位看行业热门),那么你需要进一步了解拉钩的数据接口
为了对数据有个感性认知,我们来看下数据接口,可以在你的浏览器里打开positionAjax,最好你的浏览器(chrome)装有JSONView插件,这样数据看去笔记层次分明
至于我们是如何拉钩网友接口的,这就是体力活的,通过不段尝试(每个网站不尽相同),我是通过chrome的调试工具
爬虫很简单,你读完scrapy的入门教程(中文教程)就能看懂了
我在源码里给出了参考资源
可视化部分
要理解可视化部分:jobsVisualization,你可能需要对pandas和bokeh。不过放心需要的都是入门级别的知识,稍微先过一下下门文档,遇到不懂回去查就好
bokeh
bokeh是一个非常酷的Python 交互式可视化库,在数据科学家聚集的kaggle社区,被广泛使用,bokeh非常使用用来设计数据驱动的交互式应用,而我们让用户可视化地选择合适的工作,便是典型的此类应用。
如果你对数据分析和可视化感兴趣,并向做出好玩的东西给别人试试,bokeh不容错过
pandas太过有名,就不单独介绍了
等你看完pandas和bokeh的入门教程,就可以轻松阅读这个项目啦,不到不懂google就好
这个项目也很简单,实际就是一个文件:main.py,数据源为:lagouSpider-newest.csv,这个就是我们爬虫每天爬去的职位数据,是可视化应用的数据来源
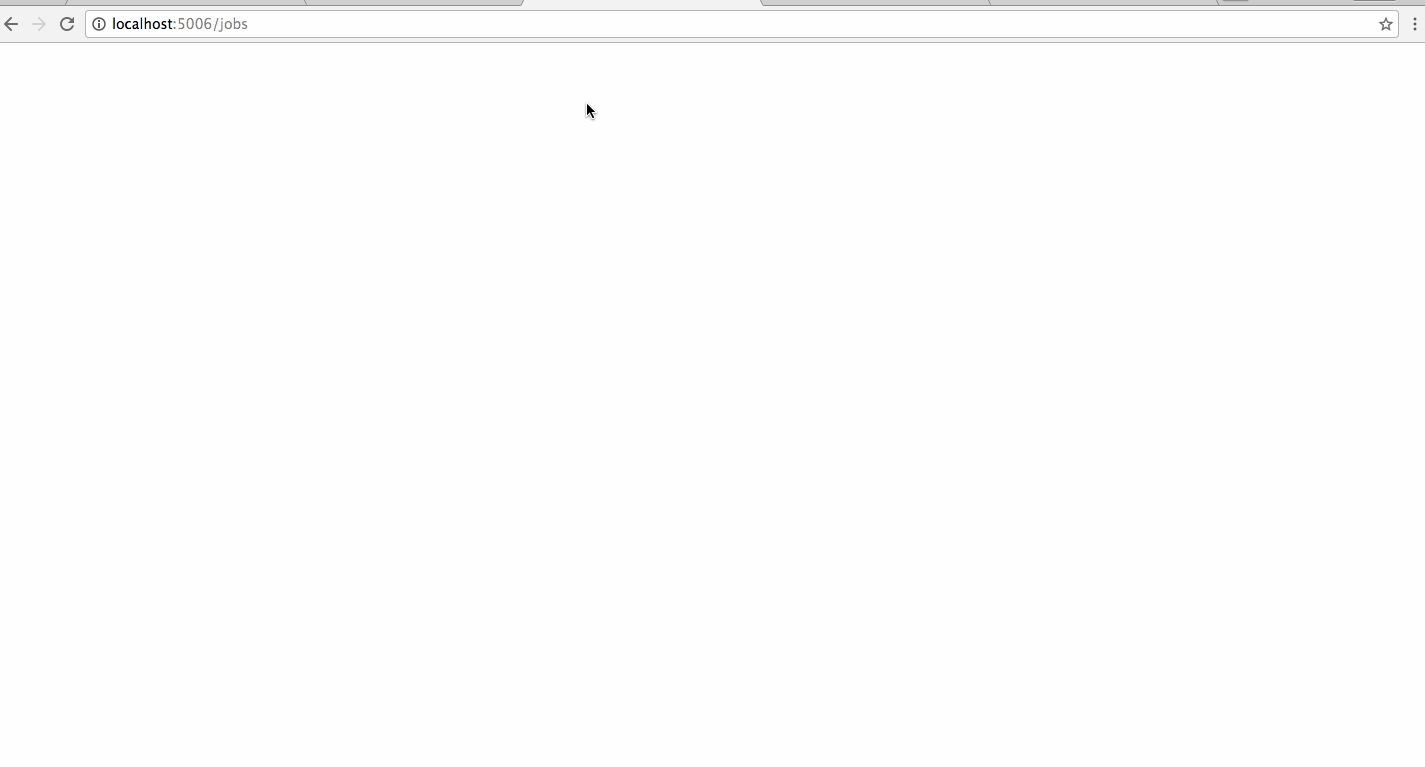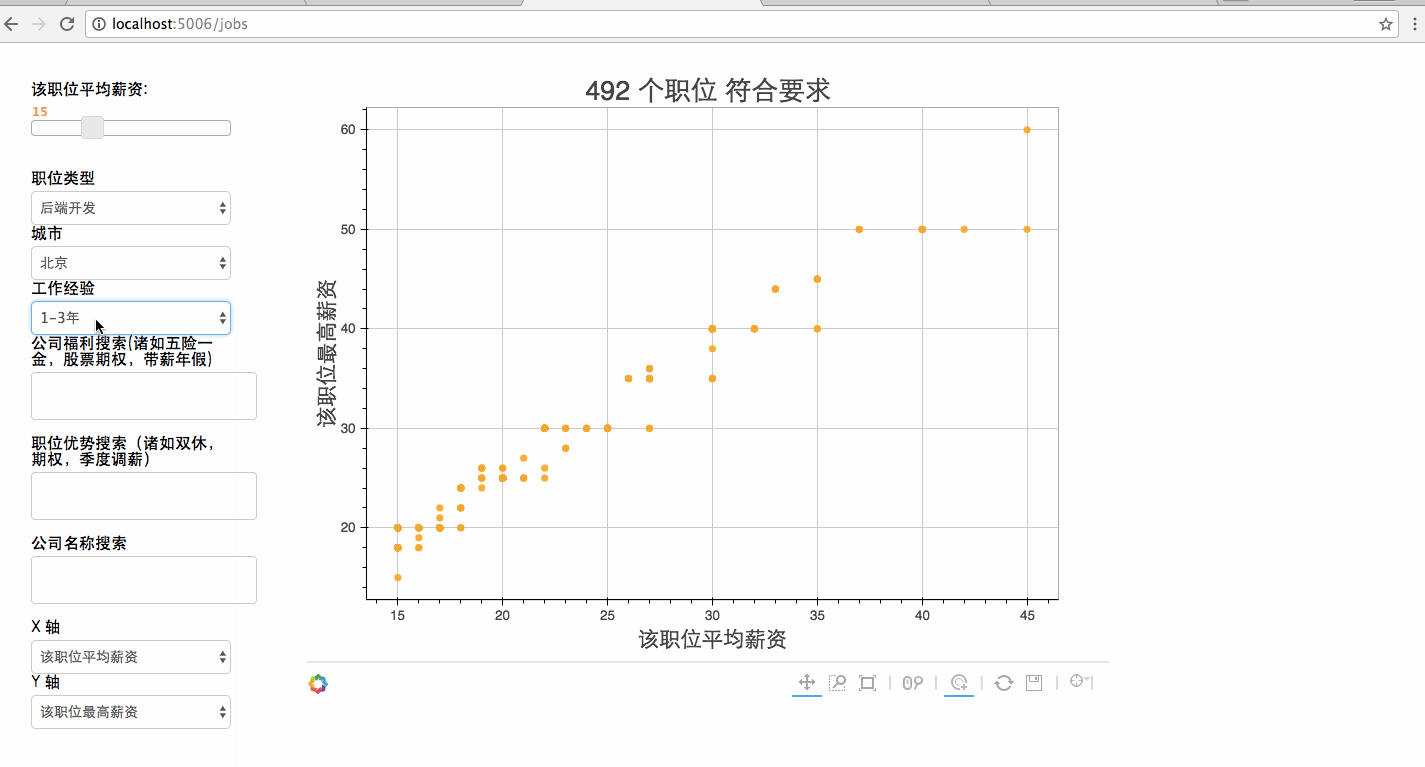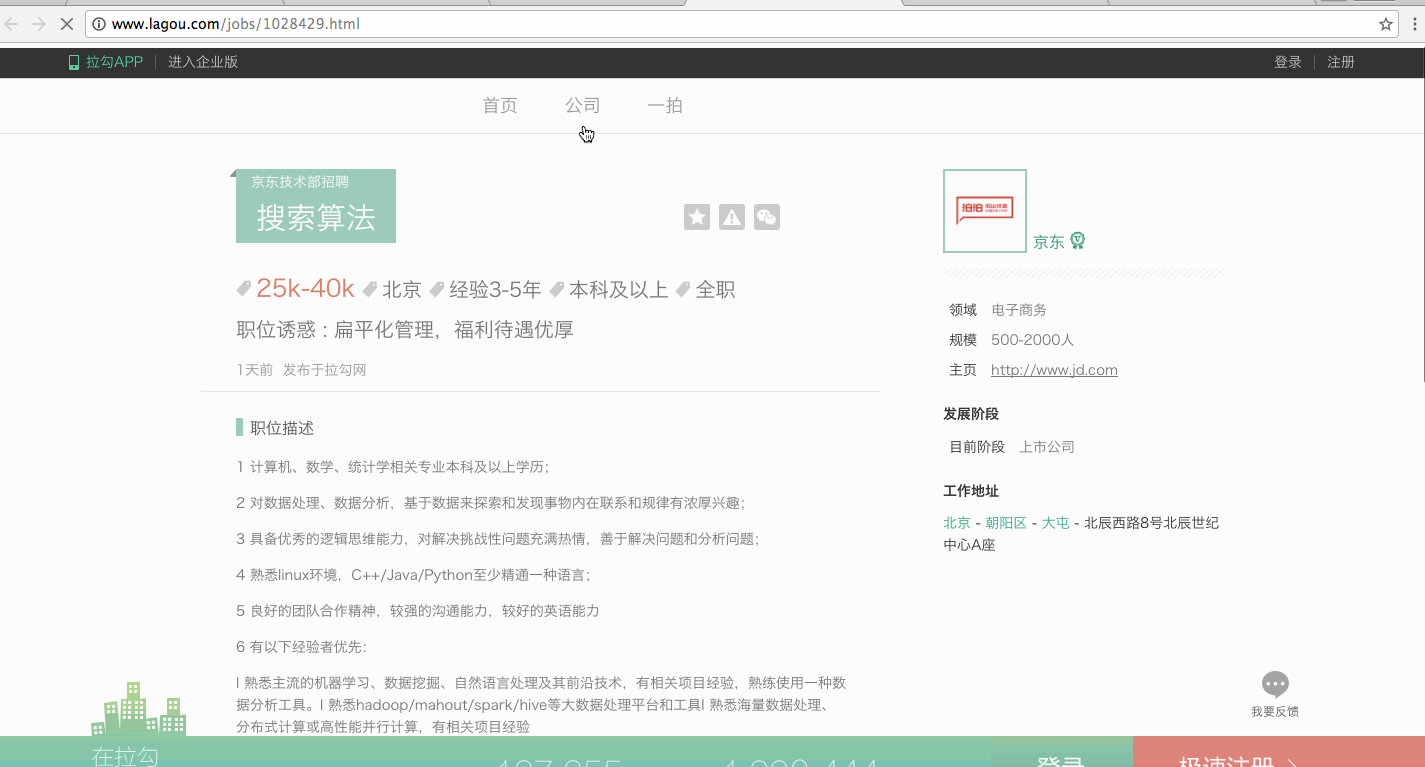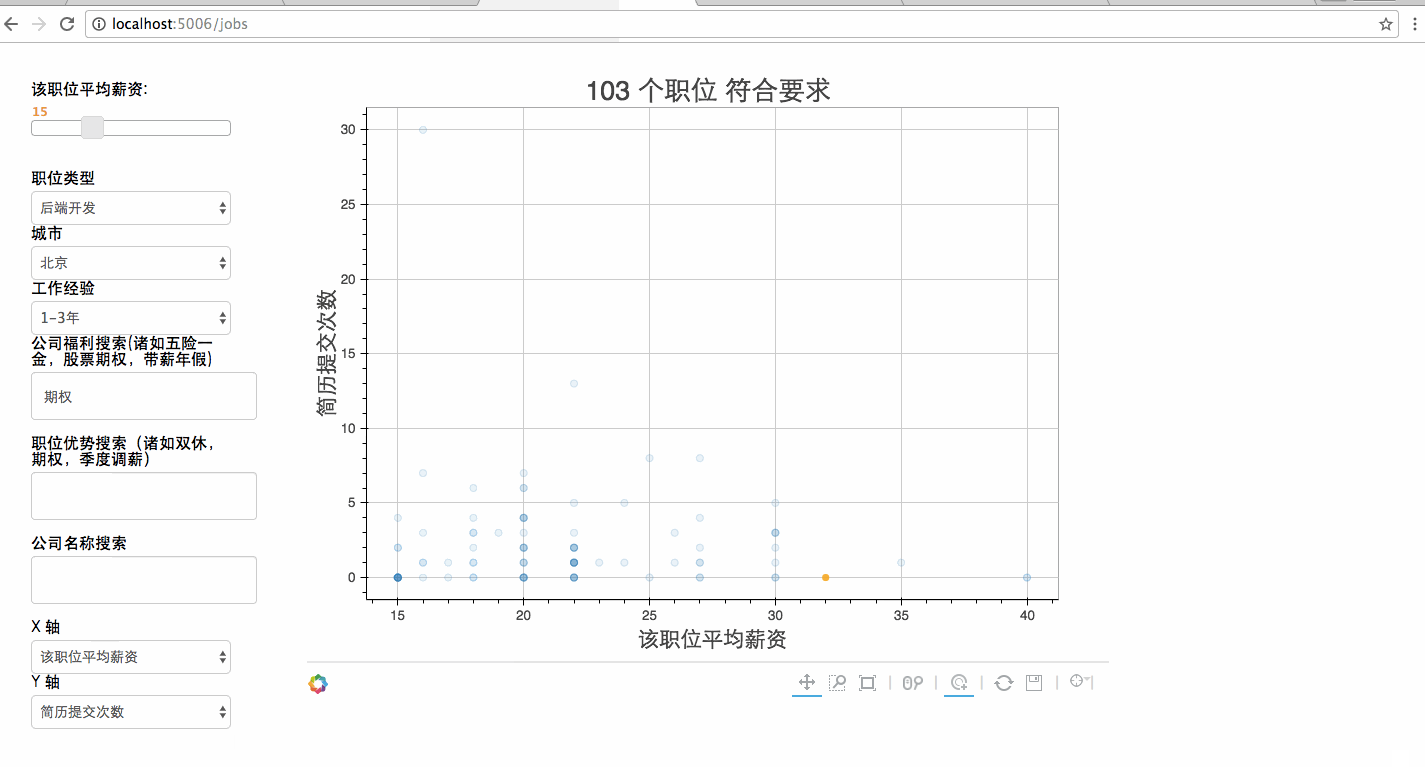
可视化部分的运作流程为:
- 用户在浏览器里选择期待的地理位置、薪资、福利
- 数据被传到后台,pandas根据用户的条件,从爬虫采集的数据里过滤出合适的,并返回
- 浏览器将这些结果可视化
- 用户直观看到合格数据在一个二维空间的分布,可以直观上进行对比选出最合适的
以上的可视化和用户界面以及数据在网络的传输这些繁琐的杂货就是bokeh做的
部署成网站!
我已经将它部署成线上应用了:jobsVisualization,你如果熟悉服务器和网站部署,也可以部署到自己的服务器上,相关文档我写在项目首页了:jobsVisualization
文章作者 种瓜
上次更新 2016-08-01