从消息和可扩展性的角度看待 Jupyter
文章目录
你不会理解某个事物,除非你从某个角度上理解了它们 – 马文·明斯基 《心智社会》
Point of View Is Worth 80 IQ Points – Alan Kay

前言
我是 Jupyter 的老用户。 一路追随它从 IPython 演进到 Jupyter, Jupyter(Notebook) 是我探索新想法时喜欢的实验场(playground)。 另几个喜欢实验场是 Lively、Etoys/Squeak、Scratch。
一直以来偏好交互式编程,它是动态媒介(计算机)为创造性想法带来的最好礼物之一。 Jupyter 提供了出色的交互计算环境,可能是交互计算的未来(假如Smalltalk依然如此小众)。
Open Standards for Interactive Computing – jupyter.org
如果你是 Smalltalk/Scratch 用户,一定深切感受过交互式编程所带来的强大力量。
Jupyter 强烈震撼使用过它的人 – 一种 人被环境所增强 的感受,这正是 个人计算 先驱们努力的方向。很可惜,流行文化并没有接纳个人计算的这种观点。
今天的计算机(尤其是移动设备)是一种与电视机相似的数字消费品,而不是增强人的环境,软件工程领域,悲惨程度也差不太多,代码看似赋予了编程者很多自由,但编程在今天,基本上是一种 闭上眼睛排列字符的游戏 (Bret Victor The Future of Programming) ,软件工程夜以继日生产一次性塑料(Alan Kay)。
缺乏可塑性和可生长性是今天软件工程和数字世界的主要问题之一,或许会演变成21世纪的软件危机。
Jupyter 已进入主流领域,却拥有不错的可塑性和可生长性。 这何以成为可能?
我们将从 消息 和 可扩展性 的角度进行分析。
与其说是一篇分析,不如说是一次探险, 记录我在 Jupyter 生态丛林里的旅行见闻。
消息视角
The big idea is messaging – Alan Kay
Jupyter 力量的源泉之一是以消息为中心的架构.
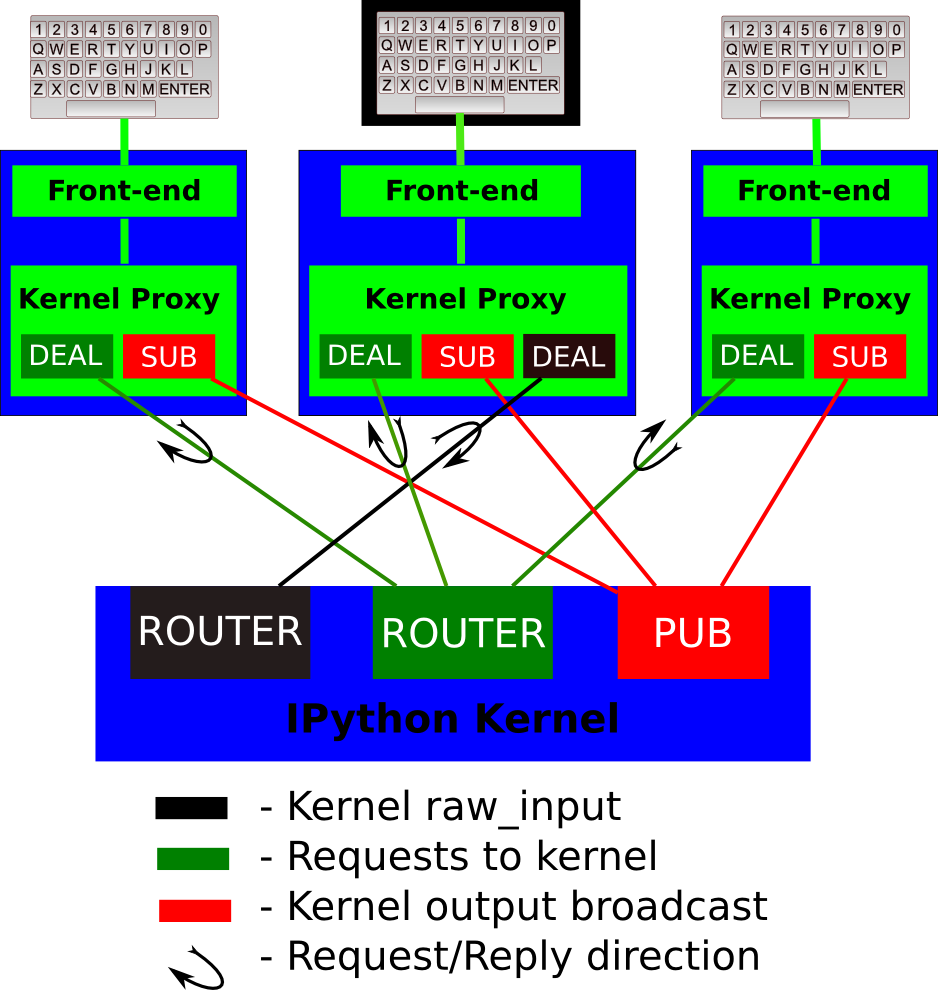
对象与消息
站在 Smalltalk 视角下,我会把 Jupyter Kernel(独立进程) 看作一个对象,这个对象通过 消息 与外部(前端)沟通,并负责解释自己理解的消息。
通过消息,将计算的 Kernel 和 交互的前端 进行分离,这种模式Smalltalk用户应该很熟悉,在 Smalltalk 中,计算发生在对象内部,它响应消息,并对此作出自己的解释,彼此交互的物体,只是互相发消息,对于各自的内部一无所知,这种隔离,导致了解耦。
Jupyter 并不关心计算的 Kernel 是什么,它可以是任何编程语言,从最早的 Python,到后来的一大堆编程语言。强大的 通信管道 + 消息结构 作为 Jupyter 坚实的地基,生长出了如今的万丈高楼,这楼还在持续拔高。
Jupyter Kernel(对象) 基本遵循 《Smalltalk背后的设计原则》 的这条原则:
应将计算视为对象的固有功能,可以通过发送消息统一调用它们。
这里用的 对象 一词,使用的是Alan Kay赋予它含义: 对象有自治能力,通过响应消息与外部世界沟通。可以把它想象成一个微型计算机(对象是计算机的递归)。另一种强有力的视角是把它看作生物学上的对象,诸如非洲草原上的一只野兔,一个活生生的对象。

Alan Kay 的 Object(对象) 与马文·明斯基在《心智社会》里构想的 Agent 很像,具有应激性。通过响应外部消息获得应激性。
如何沟通
用户在 Notebook 前端输入代码时,计算是如何发生的? 当用户在一个单元格(cell)里输入 print('hello world'), 似乎发生了一次 请求-应答(request-reply) 。
发生的事情好像是,客户端(浏览器)把用户输入的代码抛给后台的某个 Kernel,Kernel 对代码做了解释之后,把结果(output)返回给客户端。为何不用 RPC 或者 RESTful API 之类更简单方式来实现呢? 为何使用这种颇为复杂的结构:
原因是这种结构有更高的灵活性。许多场景,使用简单的 RPC 、 REST-API 难以完成。
诸如 input() ,一开始,是前端要求 Kernel 解释该消息,但该消息的语义(input)是请求前端输入,这是内核对前端发出的请求,请求-应答 的角色发生了倒置,在通常的 请求-应答 结构中,客户端发出请求,服务端负责应答,要如何处理这种倒置?
这仅是一例,不好用简单的 请求-应答 模式处理的情况还有很多。诸如在消息被解释时,发生了其他事情: 错误通知、后台任务等等…
为了适应交互计算中可能涉及的种种场景,Jupyter 采用了基于消息的架构。使用消息的另一个好处是,即使有新的需求发生(诸如最近 Jupyter对调试功能的支持,也是基于消息实现),也能很好适应(可生长性),通过精心设计消息的通信模式和消息结构,可以满足各种需求。
正是在这种灵活性,使我相信它能完成如下使命:
Project Jupyter exists to develop open-source software, open-standards, and services for interactive computing across dozens of programming languages.
刚性结构 和 软性结构
接下来,我们来考察下消息的通道(channel)(刚性结构) 和消息体(软性结构)。
Jupyter 协议中构造了5个 ZeroMQ Socket 通道(channel):
- Shell(ROUTER-DEALER): Kernel 中跑着 ROUTER, 允许多个从前端进入的连接(DEALER)。 Shell通道是前端向内核发出代码执行、对象信息、补全提示等请求的地方。
- IOPub(PUB-SUB): 这是一个 “广播通道”,Kernel在此广播所有的副作用(stdout、 stderr、调试事件等);向所有前端广播彼此向内核发送了什么(这在协作场景中很有用)
- stdin(ROUTER-DEALER): 当调用
input()时,它允许内核从前端请求输入。 前端有一个 DEALER 套接字,在通信时充当内核的“虚拟键盘” - Control(ROUTER-DEALER): 与 Shell 类似,但使用单独的 Socket,以避免排队。控制通道用于关闭和重启相关的消息,以及用于调试消息。
- Heartbeat(REQ-REQ): 在前端和内核之间发送简单的字节消息,以确保它们仍然连接。
以上只是简略概括,更多细节,参考文档
强大的结构
以上的刚性(相对固化)通信管道十分强大,Alan Kay提到过 护栏 的概念,这是我对刚性结构的力量的理解,它看似限制(因为已经成型),但实际上拥有巨大力量,由于形状被固定下来,产生的附属功能(可看作结构的属性)。这使我想起亚里士多德对 形式(form) 的论述。
这些通信管道有不同的关注点,通过 关注点分离 ,使得它们彼此互补(Shell 和 Control 管道特性一致,但关注点不同),而没有导致复杂度累积。 将 Control 分离出来是非常明智的做法, 我在设计 CodeLab Adapter 时,虽反复阅读 Jupyter 架构,却并没有领会这点,为了一致性,统一使用了 PUB-SUB ,但却缺失了 Jupyter 里一些强有力的结构。在消息层面要采用怎样的一致性,我目前依然困惑,Smalltalk 展示出来的一致性非常诱人,但我不知道应该在什么层面贯彻它,也不知道一致性原则那些时候会成为无用的教条。
Jupyter 的5个通信管道具有很好的通用性。似乎可以用来实现自治的且能够跟外部通信的对象(Alan Kay), 或者用来实施马文.明斯基的 Agent。 我目前确实打算在我的新项目 PyTalkKits 里这样做。
如果你去看 Kernel 的实现,会发现 Kernel 颇为笨重,它启动为独立的系统进程,如果想创建成千上万的对象(复现Alan Kay和明斯基的一些想法,可能都需要大量对象),完全采用 Kernel 的实现是行不通的,更令人期待的可能是 Erlang 或 Syndicate 中 spawn 出的那类轻量级进程(非系统进程)。
但我们依然可以大量复用上边5个 ZeroMQ 通道。ZeroMQ Socket是非常轻量的,可以快速启动成千上万个,只要把以上的五个通道安插到你的轻量级对象里(诸如使用asyncio task启动),就能获得很好的性能。Jupyter消息结构的精髓与 kernel 无关。
消息体(协议)
Jupyter 管道中流动的消息,其结构也经过精心设计(CodeLab Adapter 受其影响), 多年的迭代,使这个结构已足以覆盖交互计算涉及的绝大多数场景,尤为难得的是,消息的结构的设计思虑深远,对可生长性做了长足思考。 Jupyter 文档里对此有详细说明(目前已经是权威规范)。
该协议的设计,有许多地方值得学习,十分优雅。其中我最关注的是利用消息在异步中实现同步, 其中的关键是利用 msg_id 。
Jupyter 消息体为用户保留了扩展它的机制: Comm. Comm API 是一个对称、异步、忘记式的消息传递 API。它允许程序员在前端和后端之间发送消息。 Comm API 隐藏了 webserver、 ZMQ 和 websocket 的复杂性, ipywidgets 基于它构建。
理解
通过交互来理解
学习这些精心设计的结构的好方法之一,是与之交互(建构主义视角),你有很多方法与这些来来去去的消息交互,诸如写一个 message monitor 来观察消息(ROS社区对这种调试方法很熟悉),或者通过打断点(Kernel只是Python进程),或者使用Python社区偏好的 IPython.embed(), 在消息流进来时,将它带到交互式 IPython 环境下观察它。
Jupyter(Notebook) 本身就是极为强大的交互计算环境, 所以我们也可以在Jupyter中观察这些消息: 查看shell_socket的消息
使用交互式环境来探索感兴趣的东西,过程颇像一次丛林探险,它的趣味来自于好奇心指引行动,系统对你的探索作出回应,就像把石头扔向枯水期的瀑布深处,林鸟与岩层对你作出回应。这些回应引起我们进一步的探索欲。
一个复杂的系统,其迷人之处正如一个茂盛的丛林。它是孩子的乐园,即便这孩子已经成年;成年的麻烦之一是,无法随时出发去丛林,好在我们有了计算机,只消一个像 Jupyter 一样美丽而复杂的系统,我们随时可以进入这座美丽的人工乐园冒险。
交互式探索与一个人对着系统说明书,力图记忆其中的知识细节,状态完全不同。与系统交互是一种主动的冒险,它容易生出黑客精神; 在教科书里默记知识点,是对权威知识的被动吸收,这容易滋生考试狂热症。
通过阅读文本描述/定义来理解事物,许多时候只是记住了事物的名字(费曼),却让人们产生理解了该事物的错觉,今天的教育热衷于批量生产这种错觉,于是有了更糟的情况:拥有这种错觉的人进而生出傲慢,由于这种官僚系统也偏好选择他们,于是他们权力更盛,一有机会,就要指定各种考试和考级标准,逼迫别人也要这样做,认为这才是理解的正途,不仅要考倒你,在你深入系统探险时,还要斥你不务正业。杜威和派普特对此做了深入的批评。
项目式学习或许是考试狂热症的一种解药,但目前看来,官僚的教育体系并没有屈服,它试着征服项目式学习,试图在里头继续搞各种考核。 他们关注那些可考核的东西:定义、算法、在很多层的循环里把几个ijk变量搞来搞去乐此不疲。并斥责那些不可考核的东西太软不够硬,不可考核的东西有: 观点、热情、好奇心、黑客精神、深刻的洞见、想象力、分享的精神。
此外,对探险的乐趣的最大破坏就是有一条详尽之极的路线,就像你跟团旅行那样。如果打算交互式地探索 Jupyter,不必读完我前头的文章,大致了解方法,就大胆使用自己的聪明才智去探索吧。
启蒙运动是使人从自愿接受监护的状态中解放出来……在这种状态下人不依赖外在指导就不能运用自己的才智。这样一种我称之为“自愿接受”监护的状态,并不是由于缺乏才智,而是由于缺乏在没有领导帮助的情况下运用自己才智的勇气和决断。 – 《猜想与反驳》
带上一个能用的指南针就行,不需要地图,事实上也并不存在地图,事无巨细的代码不是地图,许多时候,它是一种干扰。
可是什么是指南针?你的兴趣和你的视角(view point)。
交互式探索是一个发现的过程,不存在完整的版图,期待完整版图,是多年的考试塑造的对标准答案的幻想。别想着要读完所有材料,也别担心遗漏什么东西,大胆出发,享受胡乱探索的乐趣,指引你的应该是好奇心。
追本溯源
Jupyter 消息结构,演化至今,变得优雅而美丽,但也变得复杂(有些复杂度似乎是固有的)。
理解复杂事物,除了与之互动,另一种好方法是追本溯源: 回到事物的早期形态去理解它。
这或许是柏拉图那些对话录经久不衰的原因,试图深入哲学的人或早或晚总会经过柏拉图这道门,因其简单和清晰。
Jupyter 演变自 IPython,Jupyter 的消息结构,最早可以追溯到 fperez 的 zmq-pykernel
该项目的描述非常精当:
ZeroMQ-based interactive Python kernel (aka toy-ipython)
这个项目比较老旧,我将它升级到了Python3: wwj718/zmq-pykernel
zmq-pykernel 源码短小精悍, Jupyter 中最核心的管道在一开始就想清楚了 socket(zmq.ROUTER)。这点与 Smalltalk 也类似,在一开始就把系统的核心结构想清楚了,之后在以十年为计的时间里几乎不变。
如果你觉得 wwj718/zmq-pykernel 太过简陋,其消息结构也不是真实的 Jupyter所采用的(诸如没有完成input),而 jupyter-client 又太过复杂,kernel_driver可能是你寻求的东西.
ZeroMQ 视角
Jupyter 中的每个 Kernel 都通过这五个通道与外部沟通。
站在 ZeroMQ 的视角,我们简单说下支撑上边五个通道的消息模式。
ROUTER-DEALER: 异步 Client/Server 模式
ROUTER-DEALER 是 Jupyter 使用的最重要消息模式(由ZeroMQ提供)
在ZeroMQ中, ROUTER是异步的REP; DEALER 是异步的REQ。
未来 ROUTER-DEALER 可能升级为 Client-Server, 后者具有线程安全的优点,同时保持异步的风格。
在异步的通信中,如何构造同步原语,前头已经提到: 基于msg_id.
可扩展性视角
构建软件很容易,使它生长很困难。一个婴儿一年长6英寸,无需使其停下来更新;但你却无法让波音474动态生长,因为它的设计是固定的 – Alan Kay 《计算机革命尚未发生》
Jupyter 生态拥有出色的可扩展性,这种可扩展性的来源之一是基于消息的架构。
软件颇像园艺(《Code Complate》), 需要打理。可扩展性不会自然生长出来,它是精心构造的产物。 Jupyter 可扩展性的另一来源是核心团队始终在关注这个特性,并努力在各个层面去实现它,为用户/开发者引入各种可扩展机制。 从文档和架构中,都可看出这种用心。
可扩展性在 Jupyter 生态的许多项目里都有体现。
除了可以自定义 Kernel, JupyterLab 还为我们提供了各种层面的扩展机制,以下是它的文档引导,可见其丰富程度:
- Extension Developer Guide
- Common Extension Points
- Reusing JupyterLab UI
- Documents
- Notebook
- React
- User Interface Helpers
- Extension Tutorial
- Extension Migration Guide
优秀的架构设计 + 优雅的API + 出色的文档,使其生态茁壮成长。
与 Smalltalk 的对比
这篇文章可以看作一个 Smalltalk 爱好者的个人观点。
由于消息和可扩展性,也是 Smalltalk 极为关注的话题,所以在文末,简单将 Jupyter 和 Smalltalk 在消息和可扩展性方面做个对比。
有些观点可能会惹恼 Jupyter 爱好者,我自己也是一个狂热的 Jupyter 爱好者,日常使用Jupyter的时间要远多过使用 Smalltalk 的时间,我想自辨说我的偏见并不很深。
消息层面不好作对比,因为 Jupyter 深度依赖于 ZeroMQ,由于 ZeroMQ 是语言无关的,我们也可以在 Smalltalk 中实施 Jupyter 的消息结构。 Smalltalk的消息结构处于语言最底层,《Smalltalk bluebook》在第四部分(28、29章)有谈及,我对此的了解不够深入。 所以我们把更多讨论花在可扩展性上。
Smalltalk 的可扩展性要远远高过 Jupyter,这里很重要的原因是,Smalltalk 拥有无与伦比的一致性,似乎只有 LISP 与之相近(这样说有点颠倒,似乎是LISP先影响了Alan Kay)。
系统应以最少的不可变零件组成;这些部分应尽可能通用;系统的所有部分都应聚拢在一个统一的框架中 –《Smalltalk背后的设计原则》
这种一致性使得它可以把任何东西当作一致的对象(只有极少的一些例外,虚拟机的原始(primitives)方法), 你可以使用 Smalltalk 环境提供的强大工具(Halo、Browser、Inspector)去探索和捏造它们, 这些对象在运行时,可以改变自身,更为令人震惊的是 Smalltalk 解释器、编译器、UI界面、正在运行的进程…都是可编程的对象,你可以在运行时与它们交互并修改它们,就好像是你自定义的对象!这种可扩展性极为彻底,今天的任何系统都无法与之相比。
操作系统是不适合于纳入语言的事物的集合。不应如此。 – 《Smalltalk背后的设计原则》
Smalltalk环境另一个有趣的特性是,修改后的整个对象,连同环境/系统立刻更新,不需要停机和重启,也不需要特别序列化保存这些结构复杂的对象,它们整个被保存在image,这是一种比docker image更为强大的image。你可以认为 Smalltalk 程序所处的整个世界都一起更新了。保存后,关掉整个环境: 里头可能有一些正在运行的进程,有一些还在跑动的图形,有一些编辑器还没关闭…但下次打开时,它们完全处在你离开时的状态。
Smalltalk的整个世界都是可生长的!在不停机的情况下生长!就像一个孩子,一边吃饭睡觉恶作剧,一边成长。
Jupyter 是一个分层的系统,这是一种受 Unix 文化(主流文化)影响下的软件惯用的结构, 分层结构使得扩展可以在不同的层上发生,但也导致了支离破碎,彼此依赖,时常需要停机来更新。不需要rebuild的场合,通常只是因为留出了一些插槽,如果插件形状与插槽类似,就可“动态”插入,但这种“动态”并不是 Smalltalk 的动态,它有各种各样奇怪的约束,随时可能要你重启系统。
层与层之间试图通过提供API,彼此解耦,但通常都是直接调用彼此的API,这是一种耦合。这样一来,当你有了新想法,而现有的API又无法直接支持,就需要以某种方式打破它。理论上,Jupyter的消息本该派上用场,但许多时候都无法充分发挥作用, 因为 Jupyter 没有在整个系统里贯彻 对象响应消息 的原则。
当系统有了非常多的层,每一层有丰富的文档,在你开始任何工作之前,你都得花大量世界熟悉这些特性各异的来自不同层的API, 你的心智难以理解整个系统:
如果一个系统要为创造精神服务,它必须能被个体完全理解。 –《Smalltalk背后的设计原则》
当然, Jupyter 也有很多优势,诸如庞大的社区、丰富的第三方库、现代化的界面、对热门领域(AI、数据科学)的友好支持,这导致了更好的开箱可用性…这是良好的社区氛围以及巨大的人力投入的结果。 但在架构设计上,Smalltalk 依然遥遥领先。
参考
文章作者 种瓜
上次更新 2021-04-28