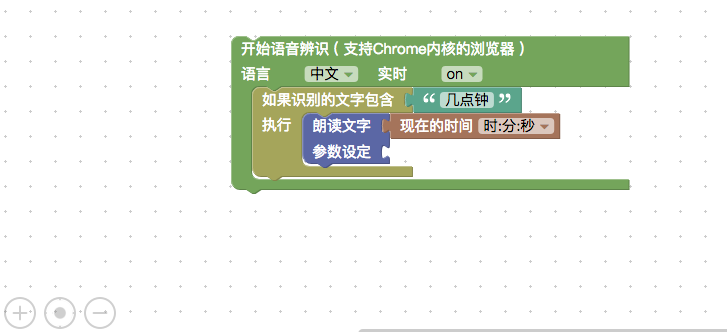
背景
近期在完善blockly4pi中AI的相关部分,语音和图像/视频流是常见的输入,语音的输入之前计划在硬件积木那边采集,之后流向树莓派,交由树莓派来处理,不过协议因此变得复杂许多,一番权衡之下,我们决定在浏览器里来处理多媒体输入
我一直在关注浏览器中的webRTC和Web Speech,之前在几个项目中也接触过它们,这些接口现在越发强大了,而且浏览器的支持也在变好
Web Speech
HTML5中和Web Speech相关的API有两类, 一类是"语音合成(Speech Synthesis)",一类是"语音识别(Speech Recognition)",无论哪种,使用起来都非常简单.
语音合成
之前语音合成我一直用百度语音来做,效果还不错,不过多了一层网络请求.
Chrome 浏览器在版本25之后开始支持这一特性,效果非常棒.你可以调出你的控制台,让浏览器说: ‘你好,世界’,像下边这样:
1
2
|
var utterThis = new window.SpeechSynthesisUtterance('你好,世界!');
window.speechSynthesis.speak(utterThis);
|
神奇的是,竟然没有用到云服务,完全在本地完成!
语音识别
相比于语音合成,语音识别还有些坑。
我们先来说下它的简单用法
1
2
3
4
5
|
var newRecognition = new webkitSpeechRecognition();
newRecognition.onresult = function(event) {
console.log(event);
}
newRecognition.start();
|
上边短短的几行,你就完成了浏览器调用麦克风,等待语音输入到结果输出的完成流程
如果你只是想拿到输出结果的内容,可以这样:
1
2
3
4
5
6
7
8
9
|
var newRecognition = new webkitSpeechRecognition();
//newRecognition.continuous = false;
newRecognition.onresult = function(event) {
//console.log(event);
result = event.results[0][0];
transcript = result.transcript;
console.log(transcript);
}
newRecognition.start();
|
识别结果比较理想
坑
有个恼人的坑是,识别开始后,浏览器有时候一直在等待输入,而无法返回识别结果(可能是墙的原因),这种情况时常发生,而且在各个平台下(mac/windows)下都是如此
不过在chrome的开发版(canary)中一切正常,我的当前版本号是: 60.0.3099.0(正式版本)canary (64 位
包装成blockly积木块
为了将其纳入到blockly4pi体系中,我们需要将Web Speech包装为blockly积木块
语音合成部分比较简单,在积木中接受用户输入,传到api中即可,@dsl已经完成了这个工作
语音识别部分会比较麻烦,在上边的语音识别示例代码里,我们看到对语音的识别结果出现在onresult事件回调的函数里,这样一来控制流就不是线性的了(哈哈 在js中这才是常态),如何在blockly中表达变达这种控制流,是个值得思考的问题
熟悉js的同学会觉得思路上不难,可要在blockly中表达也没有很容易,首先得熟悉blockly的表达习惯和api,有些部分涉及比较高级的api
这个问题webduino团队给出了漂亮的解答,我们稍后对其源码做个分析
源码分析
熟悉blockly的小伙伴,很轻松能定位到目标积木块的源码(我们只关注sound_recognition块,其他块相对简单)
在注释中我们找到了积木块的生成方式:sound_recognition blockfactory
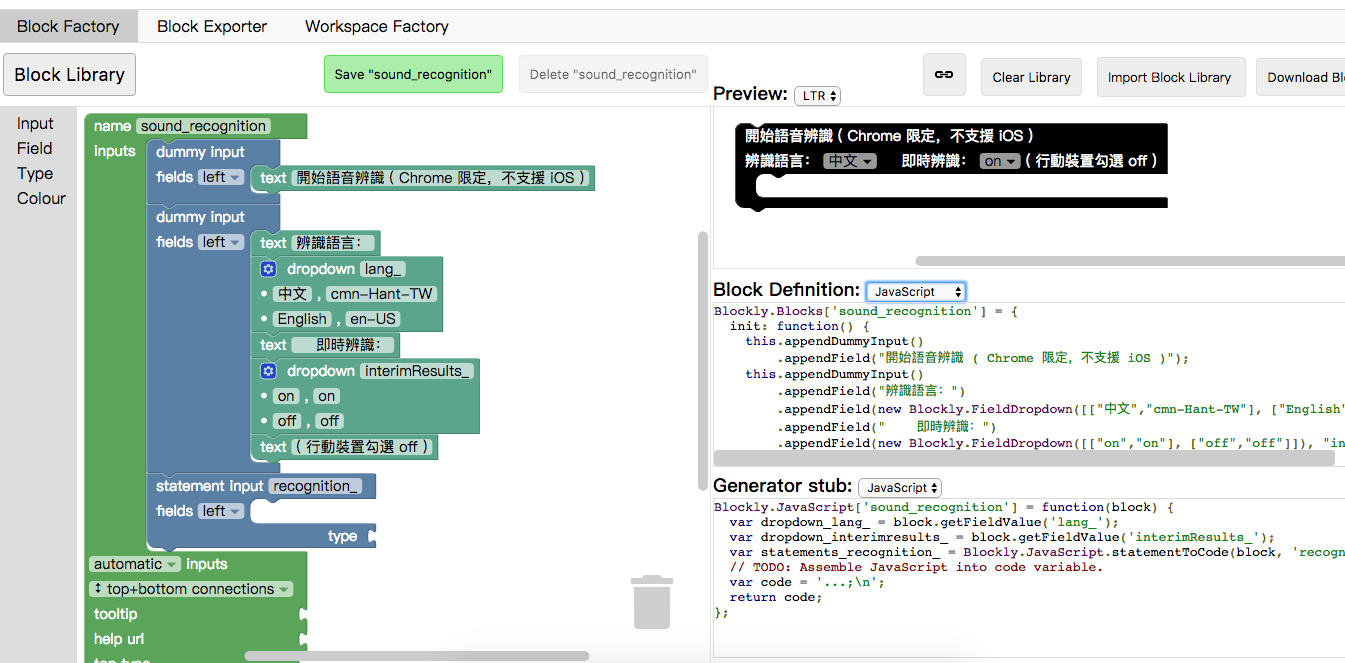
积木外观由以下代码定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
Blockly.Blocks['sound_recognition'] = {
init: function() {
this.appendDummyInput()
.appendField("開始語音辨識 ( Chrome 限定,不支援 iOS )");
this.appendDummyInput()
.appendField("辨識語言:")
.appendField(new Blockly.FieldDropdown([["中文","cmn-Hant-TW"], ["English","en-US"]]), "lang_")
.appendField(" 即時辨識:")
.appendField(new Blockly.FieldDropdown([["on","on"], ["off","off"]]), "interimResults_")
.appendField("( 行動裝置勾選 off )");
this.appendStatementInput("recognition_");
this.setPreviousStatement(true);
this.setNextStatement(true);
this.setTooltip('');
this.setHelpUrl('');
}
};
|
(以js为例)拿到积木中的用户的输入很简单:
1
2
3
4
5
6
7
8
|
Blockly.JavaScript['sound_recognition'] = function(block) {
var dropdown_lang_ = block.getFieldValue('lang_');
var dropdown_interimresults_ = block.getFieldValue('interimResults_');
var statements_recognition_ = Blockly.JavaScript.statementToCode(block, 'recognition_');
// TODO: Assemble JavaScript into code variable.
var code = '...;\n';
return code;
};
|
其中statements_recognition_值得留意
至此整个积木块已经完成,只剩下最后也最核心的问题了,sound_recognition是如何来generate出代码的,上边提到的回调的问题也是在这里处理
直接上代码更直观些:
抛开辅助性的代码,我们看到最核心的部分是
1
2
3
4
5
6
7
8
9
10
11
12
13
|
' window._recognition.onresult = async function(event,result) {\n' +
' result = {};\n' +
' result.resultLength = event.results.length-1;\n' +
' result.resultTranscript = event.results[result.resultLength][0].transcript;\n' +
' if(event.results[result.resultLength].isFinal===' + inter1 + '){\n' +
' console.log(result.resultTranscript);\n' +
' ' + statements_recognition_ +
' ' + consoleFinal1 +
' }else if(event.results[result.resultLength].isFinal===' + inter2 + '){\n' +
' ' + consoleFinal2 +
' }\n' +
' };\n' +
' window._recognition.start();\n' +
|
特别注意statements_recognition_
顺便吐个槽,尽管code的拼接极尽排版的工整,但读起来还是不舒服,用es6的模版字符串来写会好看很多
参考