PaperWeekly开发笔记
文章目录
前言
从团队相聚南京到现在,过去了2个半月,期间忙于构建社区的各个功能模块,抽不出完整的时间来对整个项目做一番梳理,十一前夕完成了PaperWeekly 1.0版本,短期内不会有大的调整,于是正好利用十一期间就技术层面 对这个阶段做个梳理
技术选型
前端
前端框架琳琅满目,在框架的选择这个话题下更是硝烟四起,好在兵荒马乱的时代渐成过往,社区对最佳实践有了更多的共识。
前端框架的选择在17年要轻松很多: 打包工具的选择上,webpack的优势很明显;编程语言的选择,也基本不必再考虑CoffeeScript之流,ES6已经足够好用和健壮,有了Babel我们也不必担心浏览器对ES6的兼容问题
至于团队协作的代码风格,大家都用ESLint就好,主流编辑器(sublime/vscode/atom/…)也都有插件支持
核心类库的选择最初在vue和react之间纠结,我自己此前用react多些,但考虑到国内的vue社区更为壮大(招人容易),且学习曲线更为平坦,最终选择了vue,当然包括它的全家桶。我们使用vue-cli作为脚手架,上边提到的ES6、webpack这些都被初始化在脚手架中
至于UI库,最终选择了element,主要的考量是github上社区的活跃程序(诸如对issue的响应速度),以及团队成员(@SoloJiang)的学长是element的维护者之一(方便交流)
后端
我们做的是AI社区,社区里Python用户居多,我个人也是Python拥趸,后端语言的选择上,自然首选Python(Python3.5)
web框架的选择,有过犹豫,早期PaperWeekly社区(pwnote)的内测版本,基于一个开源项目,该项目使用Pyramid构建,Pyramid是个特色鲜明的框架,如它在项目首页中说的
Projects with ambition start small but finish big and must stay finished. You need a Python web framework that supports your decisions, by artisans for artisans.
我们往往在项目很小的时候,喜欢小而美的框架,如Flask,而在项目变大时,又希望框架是一站式的,能提供更多基础设施及组织良好的项目结构,免得我们重造轮子,这时候我们可能就开始偏好Django,而Pyramid努力为项目的不同阶段都提供支持
Pyramid社区要比Flask和Django小得多,许多问题只能靠翻源码解决。再者出于可控性的考虑,PaperWeekly社区的1.0版本我们决定从头开始写,不基于任何现成的开源社区。我们综合考虑了:
- 社区的活跃程度
- 文档的丰富程度
- 开箱即用的功能(缓存、后台管理)
- 第三方库的数量/成熟度
当然还有个人相关的2个重要原因,其一是我对Django最为熟悉;其二是在所有python rest framework中我最偏好django-rest-framework。所以尽管Django有一些缺陷(诸如系统耦合度太高),我们最终还是舍弃了Pyramid,转向Django
前后端分离
前后端分离在今天已是主流,我们自然也不例外,后端提供RESTful风格的api接口供前端调用,接口风格我们主要参考github api(堪称业界典范),而接口文档则使用Swagger来写。
关于Swagger,我之前写过一篇文章:Swagger使用笔记
手写Swagger文档是个烦人的工作,有许多的重复劳动(诸如把model重新搬运一遍到文档里),而重复劳动令人深恶痛绝(Don’t repeat yourself)。要是有工具能自动地从项目中取出文档就好了。django庞大的社区这时候就体现出它的用处了,社区里有人贡献了django-rest-swagger。你只要在项目中定义好model,写好注释,它将帮你把接口文档自动生成出来
团队协作
git workflow
代码层面的大多数协同问题,都可以通过git解决
团队尚小,我们没有选择git-flow
而是选择了git-workflow-tutorial中描述的更为简单灵活的功能分支工作流,我们的分支命名风格为<username>/<feature>
之后结合pull requests和git rebase来做code review和代码合并
代码规范
前端代码规范采用ESLint来检验,检验不通过的,npm run dev就会报错而无法通过
后端的话,由于django runserver不会在运行时做检验,所以我们在git commit时去做检验(实际使用到了git hook),对于检验不通过的,无法commit
具体而言采用了:
- pre-commit
- mirrors-yapf
- flake8
来规范代码
结对编程与tmux
早期PaperWeekly团队以远程协作的方式办公,我们每周基本都会用tmux来结对编程或交流代码(同时开着微信语音),对于习惯在terminal里工作的同学来说,tmux提供了绝佳的协同环境。
以至于我们后来聚到一起,一室之内,需要结对编程的时候,与其围在一台电脑前,我们依然更偏好各自坐在自己的电脑前,用tmux把大家连接到同一个tmux session里
当我们需要在团队内分享知识、演示操作流程或者共同完成一些重要的操作(一人监督以防出错),tmux都是绝佳的选择
架构相关
下边对后端的架构做个概述
我们使用cookiecutter-django作为脚手架来初始化项目
Cookiecutter Django is a framework for jumpstarting production-ready Django projects quickly.
cookiecutter-django包含了Django社区的许多最佳实践,诸如项目的组织形式,常用服务的集成(sentry/celery)等等
我们对默认启用的特性做了删减,尽量不引入过多依赖(简单才灵活)
脚手架的选择上,在cookiecutter-django和cookiecutter-django-rest之间犹豫过,最终决定选择更为成熟的cookiecutter-django,对于cookiecutter-django-rest中一些优秀的特性,我们手动迁移到cookiecutter-django里(包括New Relic/mkdocs/Django Rest Framework以及用户系统)
web应用所依赖的服务(PostgreSQL/Redis/RabbitMQ/Elasticsearch/MongoDB)全部docker化,采用docker-compose up一键启动
子系统
消息系统
关于消息系统我之前写过一篇文章notification system思路、概念与实现
对社区这类应用而言,消息系统是增加用户粘度的关键部分,我最初想基于开源的Stream-Framework来构建,后来觉得它太大,考虑到可控性,决定自己写,于是利用Django的signals机制和redis来做
tracking system
我们使用Google Analytics来做网站访问数据的统计和分析,为了更细粒度地采集网站的数据(供运营使用,同时也为推荐系统提供数据源)我们设计了tracking system,将用户在网站内的行为记录到log中(tracking logs),这一块的设计思路主要借鉴了Open edX中的tracking system,我之前有写过几篇这方面的文章:
tracking logs以json形式存储在log中,使用json的原因是考虑到它的表现力和通用性(可直接供 MongoDB 和 Elasticsearch使用)
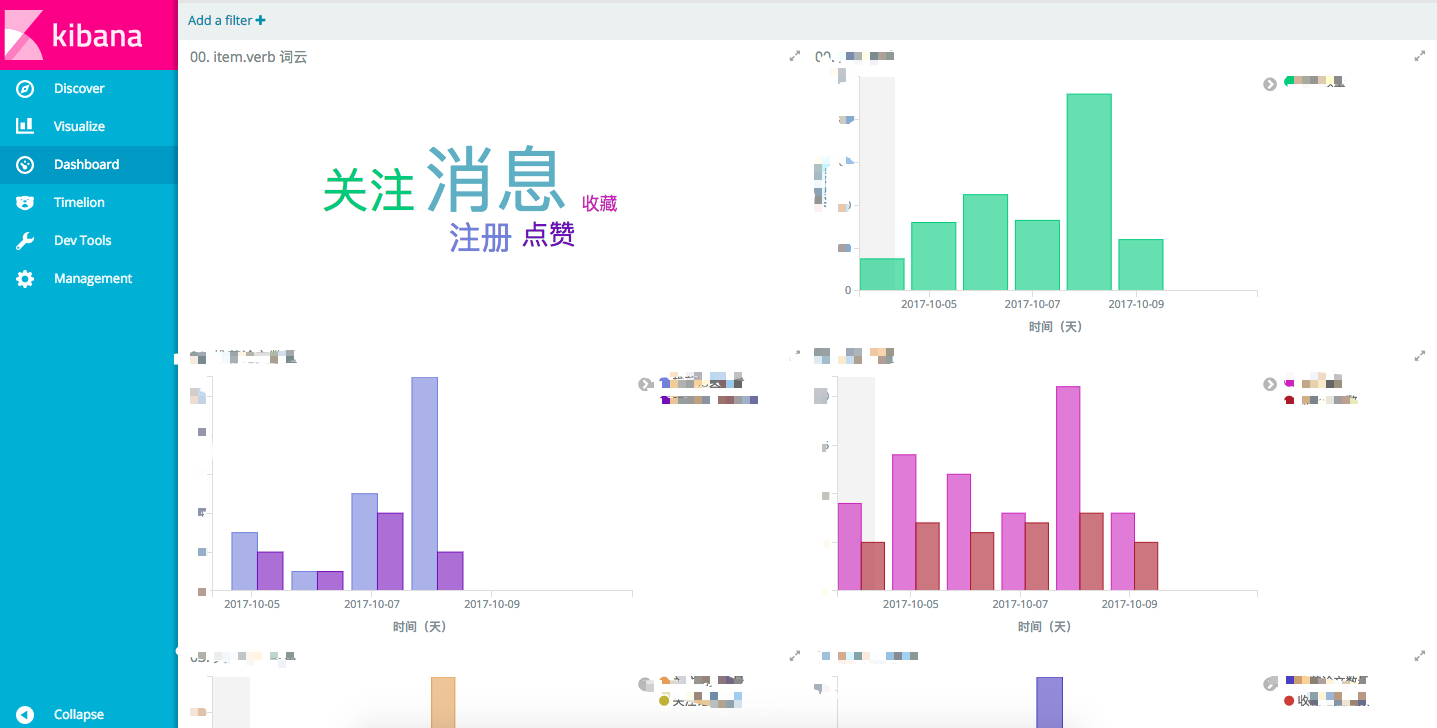
数据分析与可视化
我们在采集到tracking logs之后,就可以对其进行分析和可视化,供运营人员使用,这一块的工作也是我之前在Open edX中做过的,所以方法和工具直接挪过来就行。
因为数据量很小,不需要采用MapReduce架构,我们选择了ELK,出于对docker的偏好,我们选择了docker-elk,环境的搭建简洁至极,几分钟了事
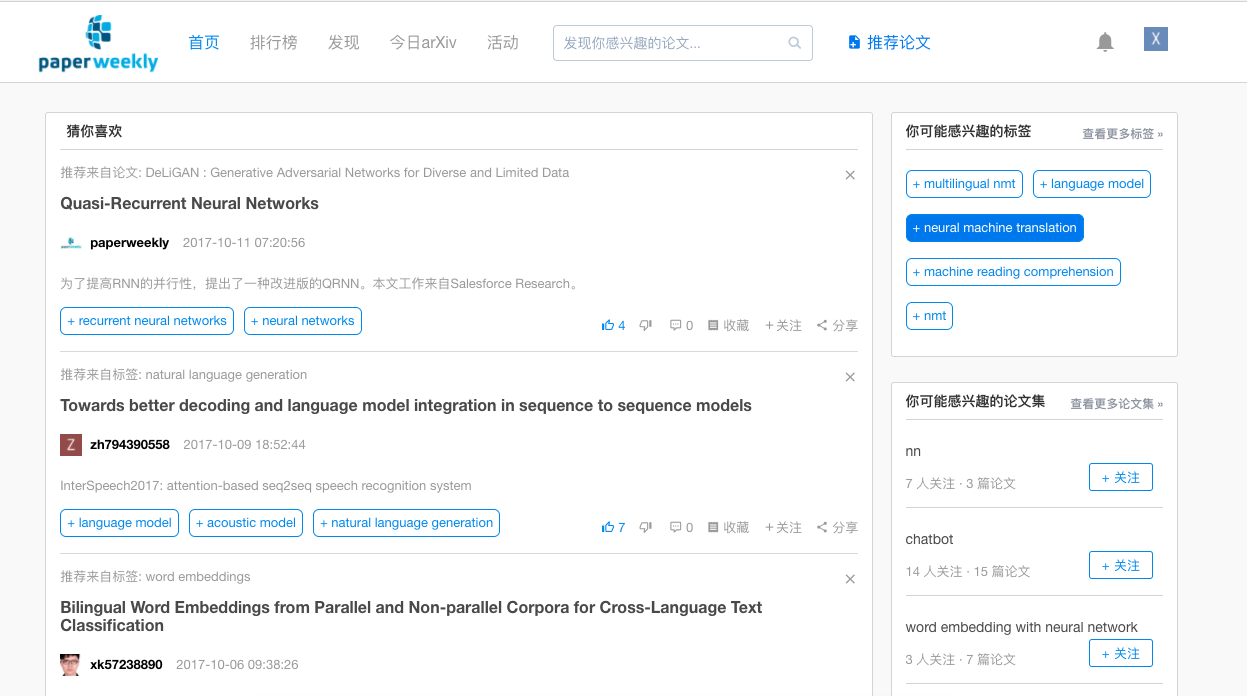
feed流/推荐系统
用户主页如上所示,我们在首页将给用户推荐他可能感兴趣的papers/tags/collections
tracking logs除了作为数据源,用来做网站访问的统计和可视化,也作为feed流/推荐系统的数据源。
我们通过挖掘用户产生的tracking logs,从而得出他近期的兴趣所在,用于个性化地推荐他可能喜欢的东西,喜欢这个概念是通过计算向量化后的元素(user/paper/tag/collection)之间的距离(余弦相似度)得到的
网站内的核心元素已经全部向量化,存储在Redis中,当实体变更(create/update/delete)时,它的向量表示也将实时更新。所以我们可以很轻松地计算网站内任何两个东西的相似度
网站内有多处推荐系统的应用:
- 当用户喜欢一个标签时,我们将给他推荐相似的标签
- 当用户推荐一篇论文时,我们将推荐这篇论文可能属于的tags
- 当用户在网站内产生活动时,我们将在首页给他推荐感兴趣的内容(feed流)
工程上,从tracking logs中生成feed流的过程是在一台独立的主机上做的,以定时任务的方式运行
全文搜索
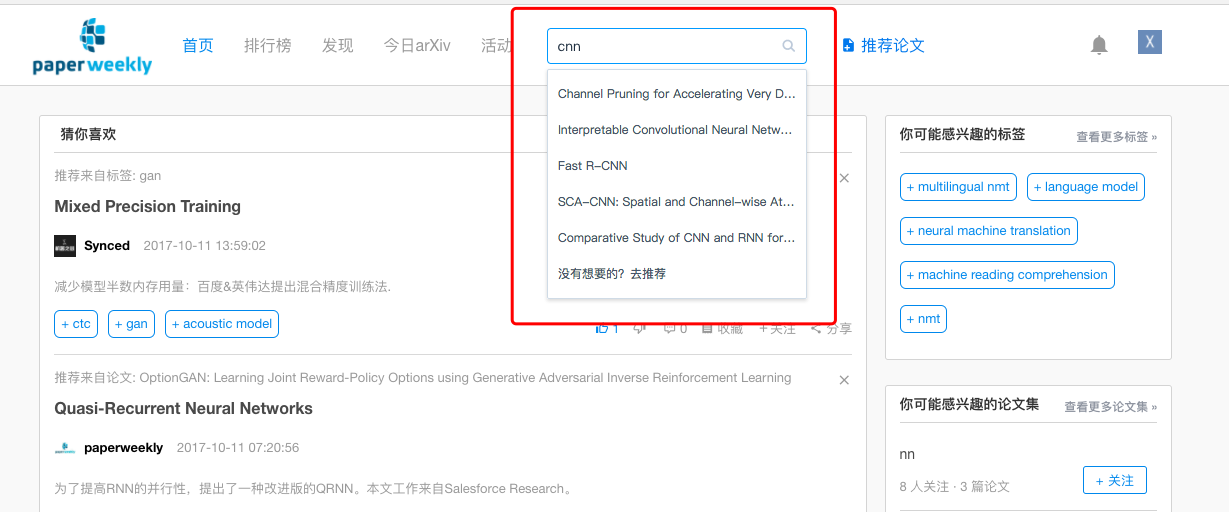
站内的全文搜索,用到Elasticsearch ,为了更方便地在Django中使用Elasticsearch,我们选择了django-haystack,django-haystack和Django协同地非常好,api风格和Django ORM基本一致
为了让Elasticsearch中的数据和PostgreSQL实时同步,我手写了同步更新机制,使用了django signals,写起来十分简单
另外,和通常的做法一样,网站内的more like this功能也是用Elasticsearch来实现的
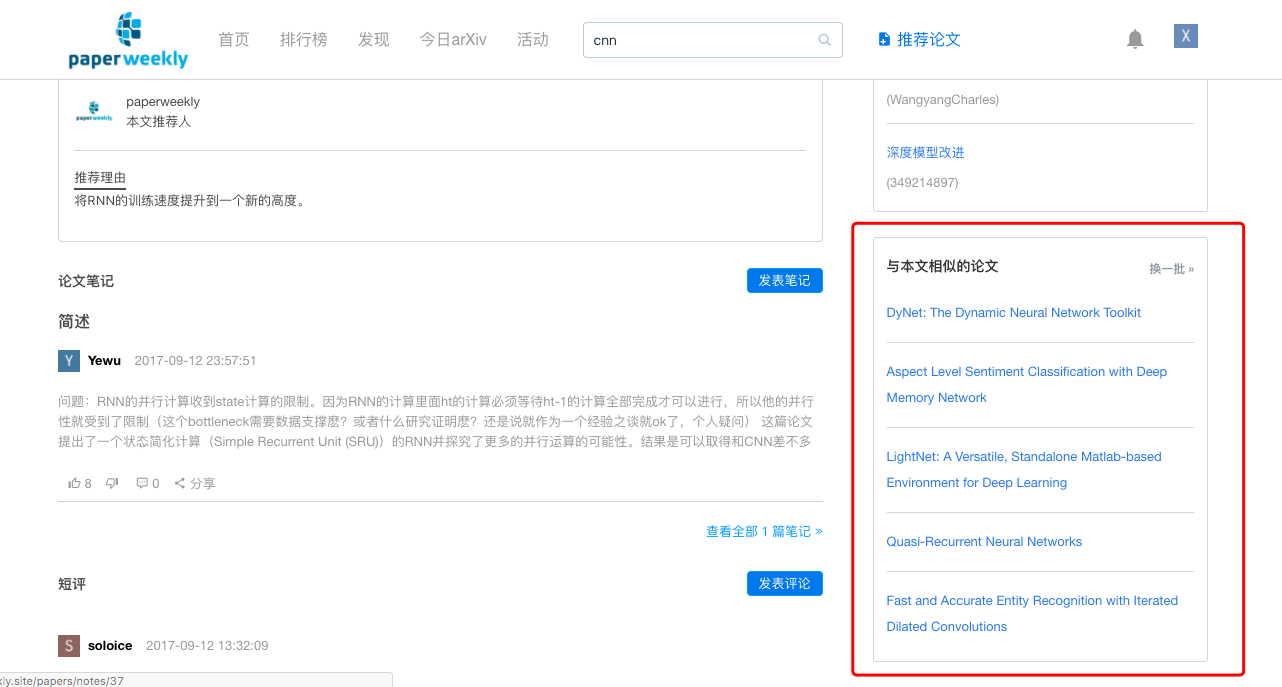
错误跟踪与报告
我们选择Sentry作为项目的实时错误报告工具
实时错误报告有助于及时发现线上系统出现的问题,让开发者能及时发现、及时修复bug。任何生产环境都能从使用Sentry中获益
Sentry本身是用Django写的,源码开放,可自行搭建
由于我们服务器部署在香港(为了海外用户能方便访问),所以我们直接使用Sentry的云服务,免去了自己的安装和维护,Sentry的实时提醒(邮件)和定期报表功能十分优秀!
性能监控
性能监控也是生产环境应当考虑的问题,尽早发现性能瓶颈和隐患有助于提高web应用的使用体验
我们在
三者中犹豫过,最终选择new relic来监控我们的应用性能, new relic的监控面板中显示,我们RESTful api的响应时间都在80ms以内(当然不包括与外部服务器通信的接口,诸如微信相关的接口)
在python项目中使用new relic非常简单,参考https://docs.newrelic.com/docs/agents/python-agent/installation-configuration/python-agent-integration
定时任务
我们在两处用到定时任务,其一是每日爬取arxiv的更新新数据,用于今日arxiv栏目
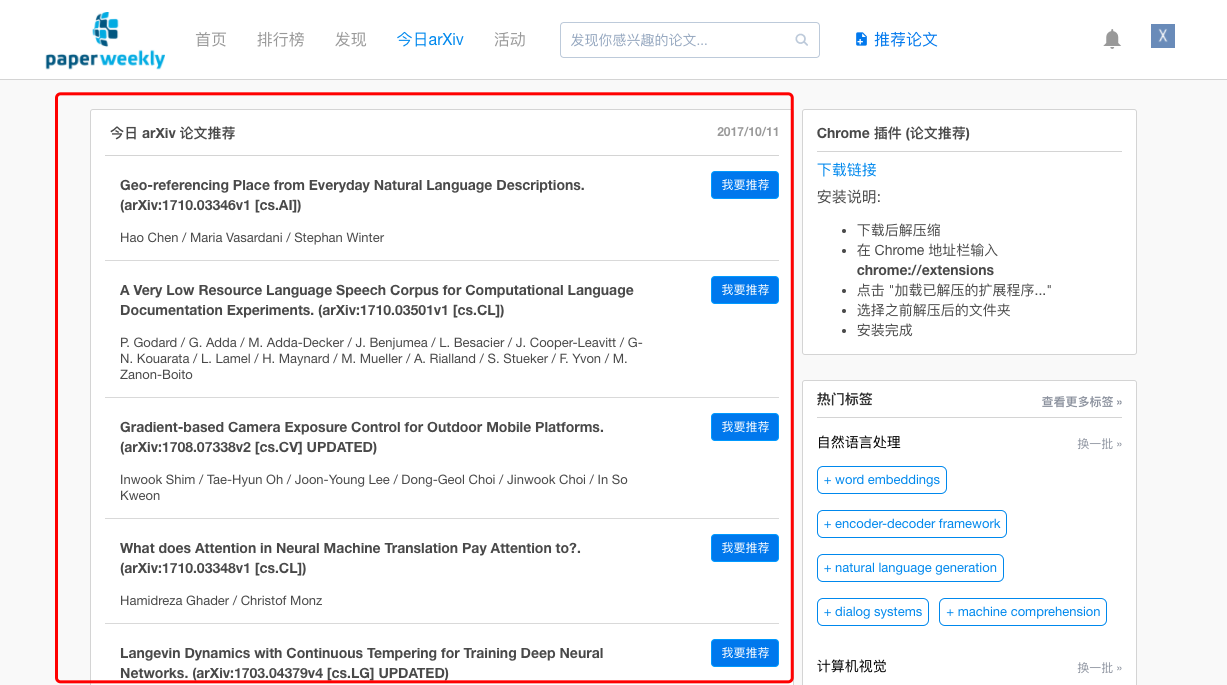
其二是在为用户生产首页feed流时,也用到定时任务
定时任务没有使用Celery Beat来做,而是选择了更为轻量级的schedule。schedule 只负责定时任务,而不管任务失败与否,是小而美的一个库(do one thing and do it well)。schedule的api和文档都非常漂亮,相比于linux crontab,我更喜欢schedule
一些好用的工具
开发过程中一些好用的工具,也记录一下
tmux
前文已经提及,就不赘述,这是我们最喜欢和常用的工具之一
关于tmux的更多信息可以参考我的这篇文章
jupyter notebook
每个程序员的工具箱中,都有一些自己格外偏好的工具,jupyter notebook对我而言是不可或缺的那种
我们目前在开发PaperWeekly社区时,广泛用到jupyter notebook,从debug到数据的分析和探索,我们都习惯将探索过程保存为ipynb,纳入源码中,即是文档,又方便日后的重用和交流
通过python manage.py shell_plus --notebook 即可在jupyter notebook中调试和探索Django应用
顺便一提,董伟明在《Python Web开发实战》提到jupyter notebook在豆瓣东西的应用场景很有意思值得一看
ps:《Python Web开发实战》一书分享了许多宝贵的Python Web开发经验,十分值得一读。我们也采用了其中的许多建议,包括一些工具的推荐和经验参数的设置(如celery)
wdb
相比于pdb,ipdb要好用很多,而相比于ipdb,我更喜欢wdb
wdb的出众之处在于,它利用web技术,提供直观而友好的UI(在对象的打印样式上,wdb利用web技术做的十分惊艳),它让你不需要记住一堆的命令,就能在错误的上下文中轻松穿行,直至找出问题所在
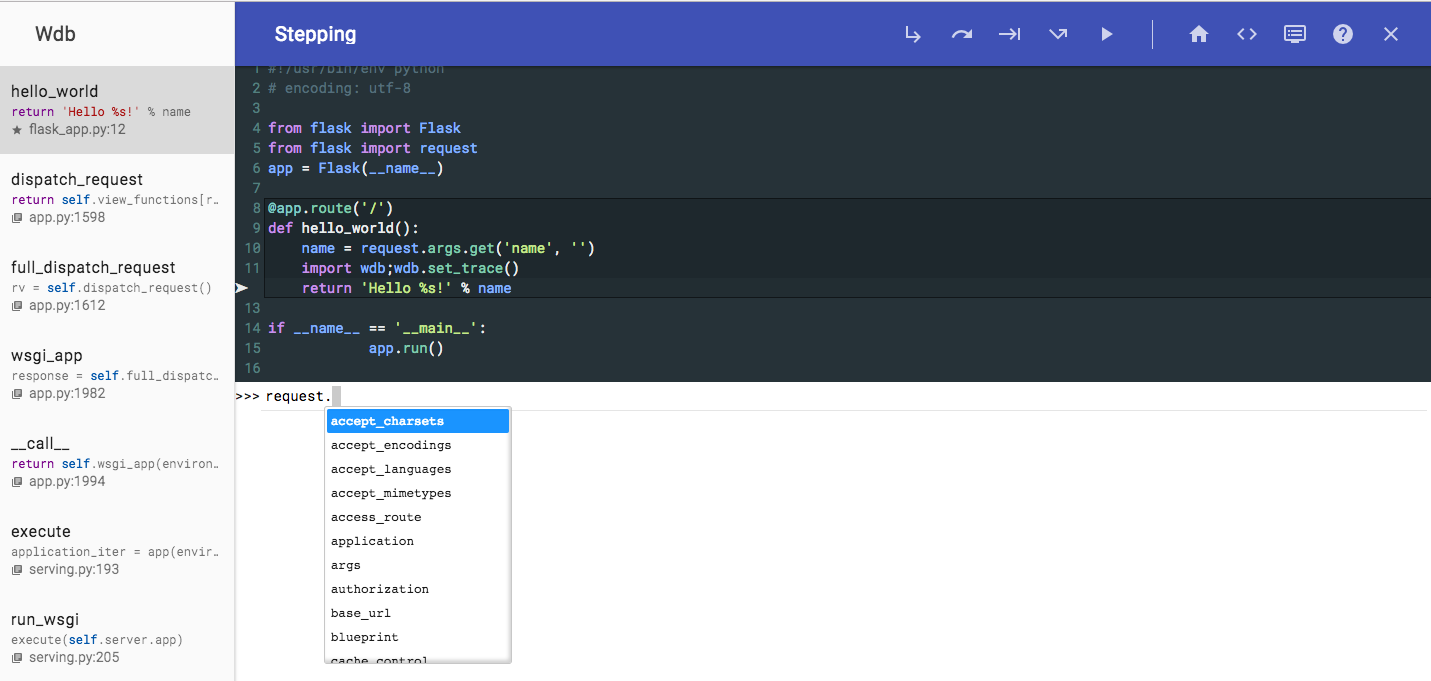
关于wdb的更多内容,可以参考:使用wdb来调试python程序
文章作者 种瓜
上次更新 2017-10-02