Snap! 使用笔记: 探索数据
文章目录
前言
Snap! 是出色的个人计算环境。
本文是在 Snap! 中探索数据的笔记。
之前一度喜欢在 Jupyterlab 中探索数据,因其出色的交互性。
Snap! 拥有更强的交互性, 数据几乎触手可及, 仿佛可以将手伸入计算机里把玩它们。
现在, 每当有探索数据的需求(它们通常是 CSV 或者 JSON 格式), Snap! 是我的首选环境, 它能够轻松处理数以百万计的数据。由于其对函数式编程以及 hyperblock(操纵多维列表) 的强大支持, 可以异常轻松而直观地操控结构化数据, 比我之前不停查阅 pandas/numpy 文档轻松许多。
当需要对正在探索的数据进行可视化时, Snap! 总是给我惊喜, 其简易和直观性, 让我可以直接摆弄图形, 直到它们符合我脑子中对数据的看法。
在 Jupyterlab 和 Snap! 中探索数据时,心态是不大一样的。
在 Jupyterlab 中, 通常会处在一种寻找现有功能的状态, 花大量时间弄清楚有哪些操纵数据的方法, 有哪些可视化的典型图表(一些带有图示的 CheatSheet 通常很有帮助), 一旦我的想法与这些内置在库里的功能不完全一致,就需要去 Stack Overflow 和 Github 里寻找各种技巧,有时找不到现成的技巧,就得一头扎到很深的地方看看如何调整代码。我有大量的时间花在工具本身上边,而这些技巧在开始下一个项目时,又忘得差不多了。这是一种不断适应工具的状态,而且经常是一种削足适履的状态。
这是我之前在 Python 生态里做的一些数据探索和可视化项目:
在 Snap! 里,探索数据和可视化充满了乐趣。我总是处在与数据的亲密关系中, 直观地摆弄和自由地思考它们。 所有的交互都是 lively(活性)的。Snap! 虽是我和数据之间的计算媒介,但我从不觉得它是负担,大多数时候几乎忘了它的存在,当我需要它提供计算能力时,总是凭直觉去做就好了。它小巧直观,所有的积木都在界面上,没有"藏在深处"的技巧,这些积木数量不多,但极为通用(来自 Lisp 的馈赠), 以至于没有了不停查阅文档的心智负担(这非常打断思绪)。
一个简单例子
Snap! 主要使用列表操控数据, 这来自 Lisp 传统。
以下是我早期使用 Snap! 列表积木探索 json 数据的例子。
一篇博客文章的数据结构:
|
|
在 Snap! 中玩耍它:
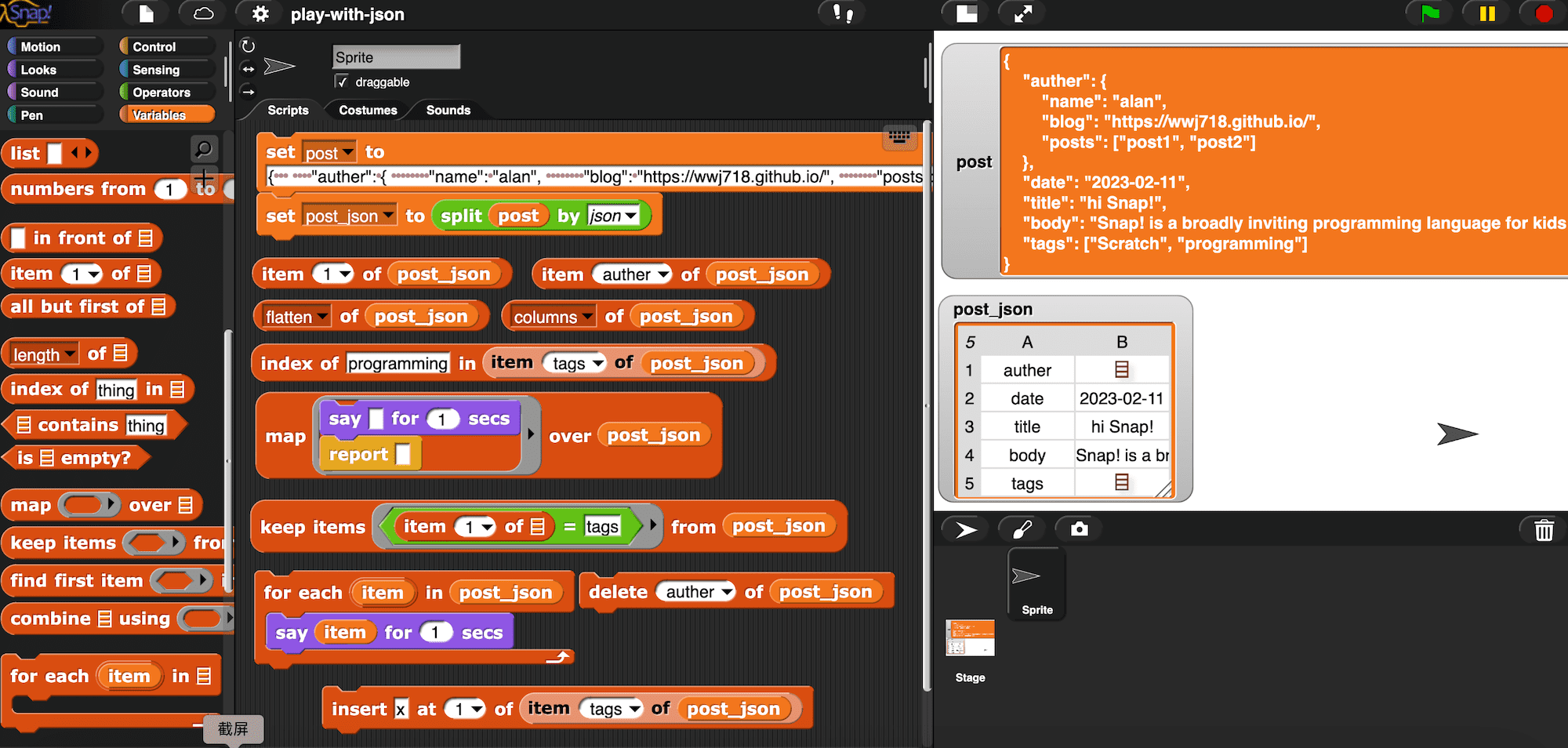
这是项目的在线地址
例子: 每日名言(Quote of the day)
Snap! 作者分享了在 Snap! 中使用探索 qod(Quote of the day) RESTful api.

这是这个 API 返回的 json 数据(每日的名言不同,但数据结构是一样的)
|
|
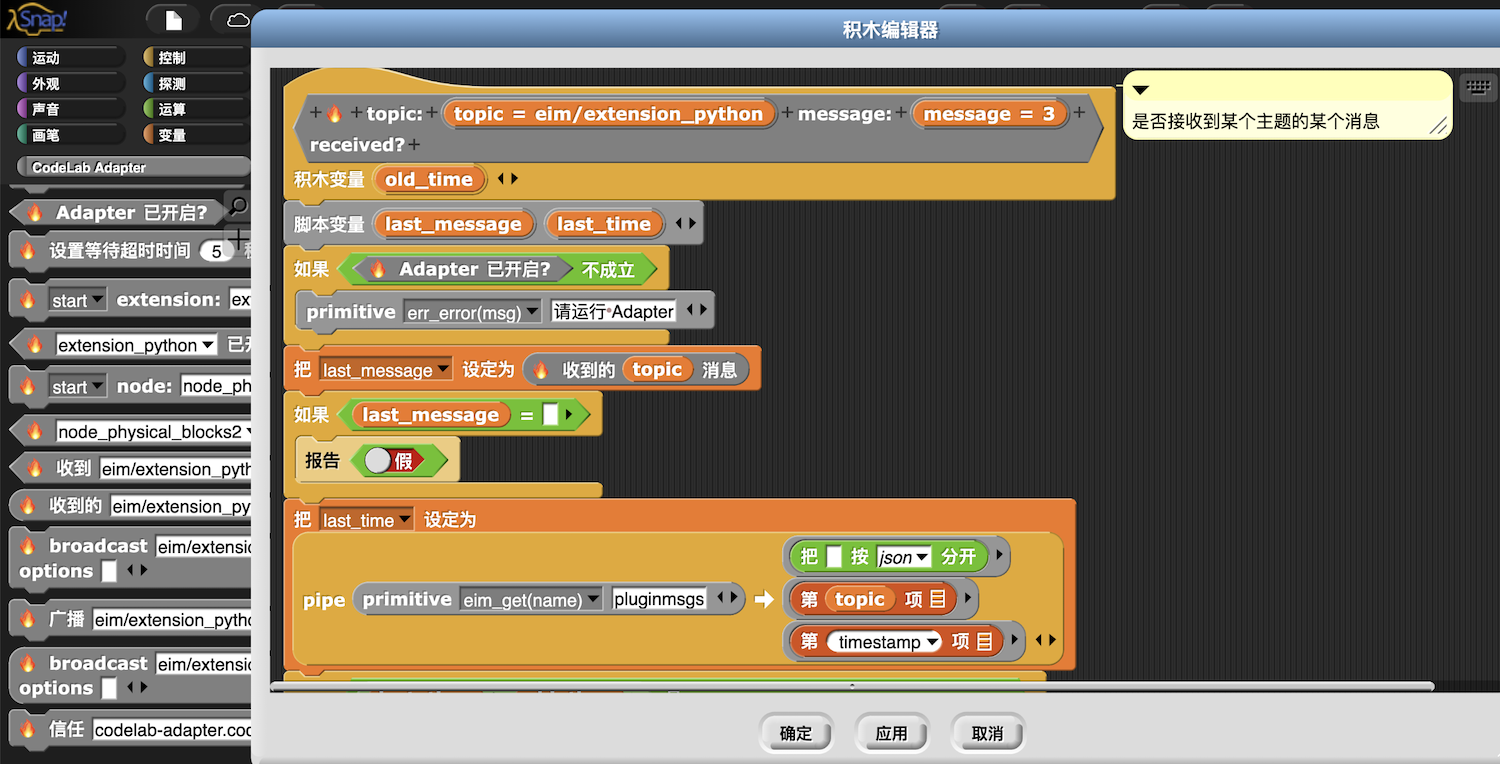
例子: Snap! 的 CodeLab Adapter 插件
我近期将 CodeLab Adapter 插件,陆续迁移到了 Snap! 中。
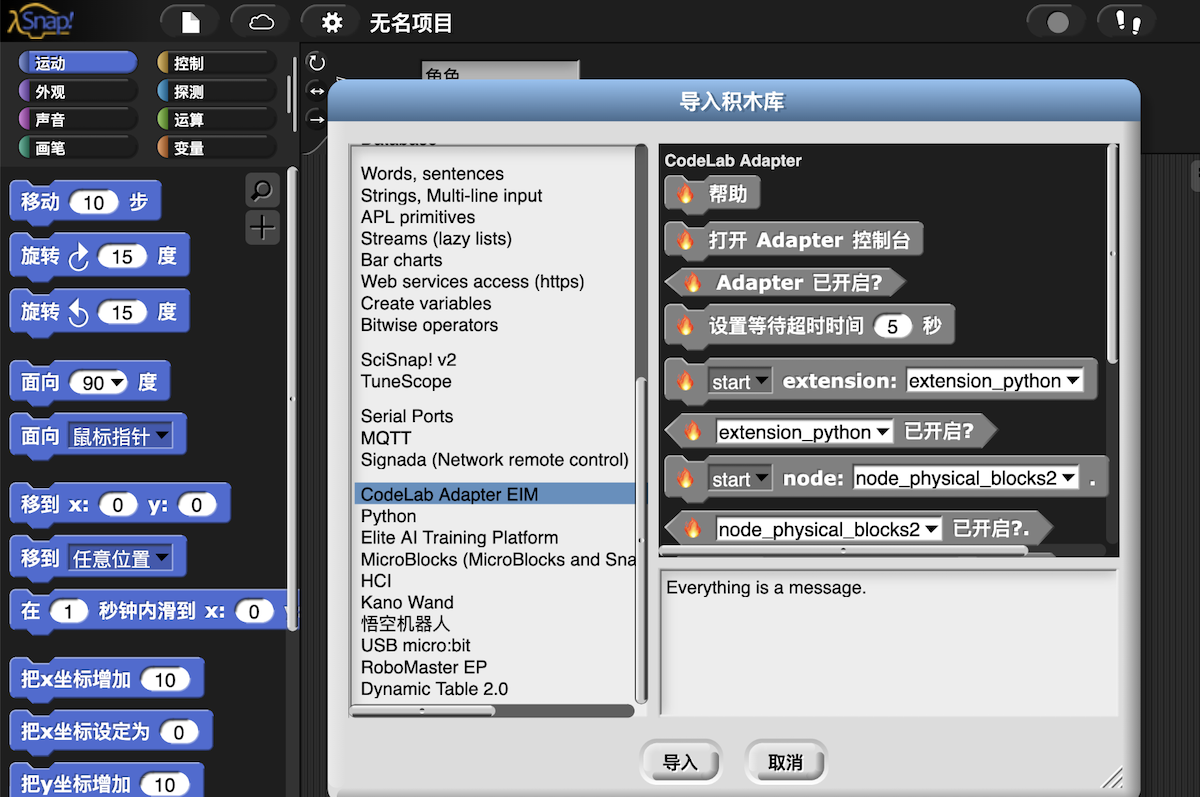
对 Snap! 而言, CodeLab Adapter 是一个本地 web 服务(提供 websocekt 服务), 采用 json 作为数据传输格式。为了给 CodeLab Adapter 下发命令、获取信息(功能实现在消息的语义里),需要在 Snap! 中操纵 json 数据。你可以通过查看 CodeLab Adapter 相关积木的定义, 来查看这些 json 数据的处理过程:
参考
文章作者 种瓜
上次更新 2023-02-22